Audiovisual Whisper (AVW) Corpus:
The MSP-AVW is an audiovisual whisper corpus for audiovisual speech recognition purpose. The MSP-AVW corpus contains data from 20 female and 20 male speakers. For each subject, three sessions are recorded consisting of read sentences, isolated digits and spontaneous speech. The data is recorded under neutral and whisper conditions. The corpus was collected in a 13ft x 13ft ASHA certified single-walled sound booth, illuminated by two professional LED light panels.
 |
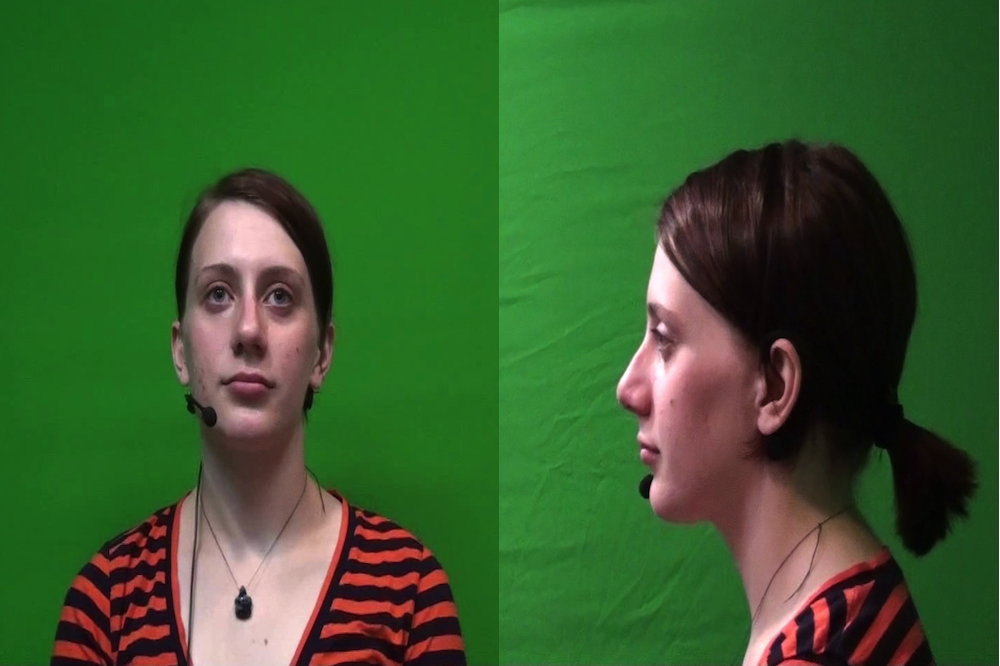 |
The audio is recorded with a close-talk microphone at 48 kHz; the video is collected with two high definition cameras which provide 1440 x 1080 resolution at 29.97 fps. One camera captures frontal view of the subjects including shoulder and head. The second camera captures profile view of the subjects
The corpus contains three parts with suitable breaks in between. In the first part, the subjects are asked to read sentences in whisper and neutral mode. We selected 129 TIMIT sentences. A fixed subset of 30 sentences are used to record read speech in both whisper and neutral modes. This subset is used across speakers. In addition, we randomly selected 60 sentences per subject which are read in either whisper (30 sentences) or neutral (30 sentences) modes. Altogether, each subject read 120 sentences, which were presented in blocks of ten sentences alternating between modes – ten sentences in neutral mode followed by ten sentences in whisper mode. We implement this protocol to reduce the fatigue caused by whispering over long periods, and the cognitive load associated with switching too often between modes. In the second part, the subjects are asked to read isolated digits (i.e., 1-9, "zero", and "oh"). Each digit is read ten times in each mode producing 220 samples per speaker. Similar to the sentences, the order of the digits is randomized per subject and presented in blocks of ten, alternating between modes. In the third part, we collect spontaneous speech. The subjects are asked to respond to general questions. Each subject selected 10 out of 15 questions. After the selection, the questions are randomized and presented alternating between whisper and neutral modes. The average duration of their answers is 45 sec. The duration of each session is approximately 1 hour, including breaks. Some aspects of the protocol were adjusted as we collected the corpus (e.g., fixing the common sentences that are read in neutral and whisper mode across subjects, and the number of sentences and digits).
The corpus is described in:
- Tam Tran, Soroosh Mariooryad, and Carlos Busso, "Audiovisual corpus to analyze whisper speech," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, May 2013, pp. 8101-8105. [pdf] [cited] [bib] [poster]
Release of the Corpus
The corpus is now available under an Academic License. Please download this pdf. The
form need to be signed by the director of the research group. Send the signed form to Prof. Carlos Busso - ![]()
Instructions:
- Please copy the group leader or laboratory directory in your email.
- Add the group leader or laboratory directory to the list at the end of the agreement. Add full name, signature and title.
- Use your institution email to contact us.
Some of our Publications using this Corpus:
- Tam Tran, Soroosh Mariooryad, and Carlos Busso, "Audiovisual corpus to analyze whisper speech," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, May 2013, pp. 8101-8105. [pdf] [cited] [bib] [poster]
- Fei Tao, John H.L. Hansen, and Carlos Busso, "Improving boundary estimation in audiovisual speech activity detection using Bayesian information criterion," in Interspeech 2016, San Francisco, CA, USA, September 2016, pp. 2130-2134. [pdf] [cited] [bib] [slides]
- Fei Tao, John H.L. Hansen, and Carlos Busso, "An unsupervised visual-only voice activity detection approach using temporal orofacial features," in Interspeech 2015, Dresden, Germany, September 2015, pp. 2302-2306 [pdf] [cited] [bib] [slides]
- Fei Tao and Carlos Busso, "Lipreading approach for isolated digits recognition under whisper and neutral speech," in Interspeech 2014, Singapore, September 2014, pp. 1154-1158. [pdf] [cited] [bib] [poster]
Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.