MSP-Conversation corpus:
A large naturalistic speech database with emotional traces
The MSP-Conversation corpus contains interactions annotated with time-continuous emotional traces for arousal (calm to active), valence (negative to positive), and dominance (weak to strong). Time-continuous annotations offer the flexibility to explore emotional displays at different temporal resolutions while leveraging contextual information. Release 1.0 contains 74 conversations with duration between 10-20 minutes (more than 15 hours). The conversations have been annotated by at least five workers. This is an ongoing effort, where our plan is to increase the size of the corpus. We have already identified 52 new conversations that we have started to annotate for the second release (28hrs 15min in total).
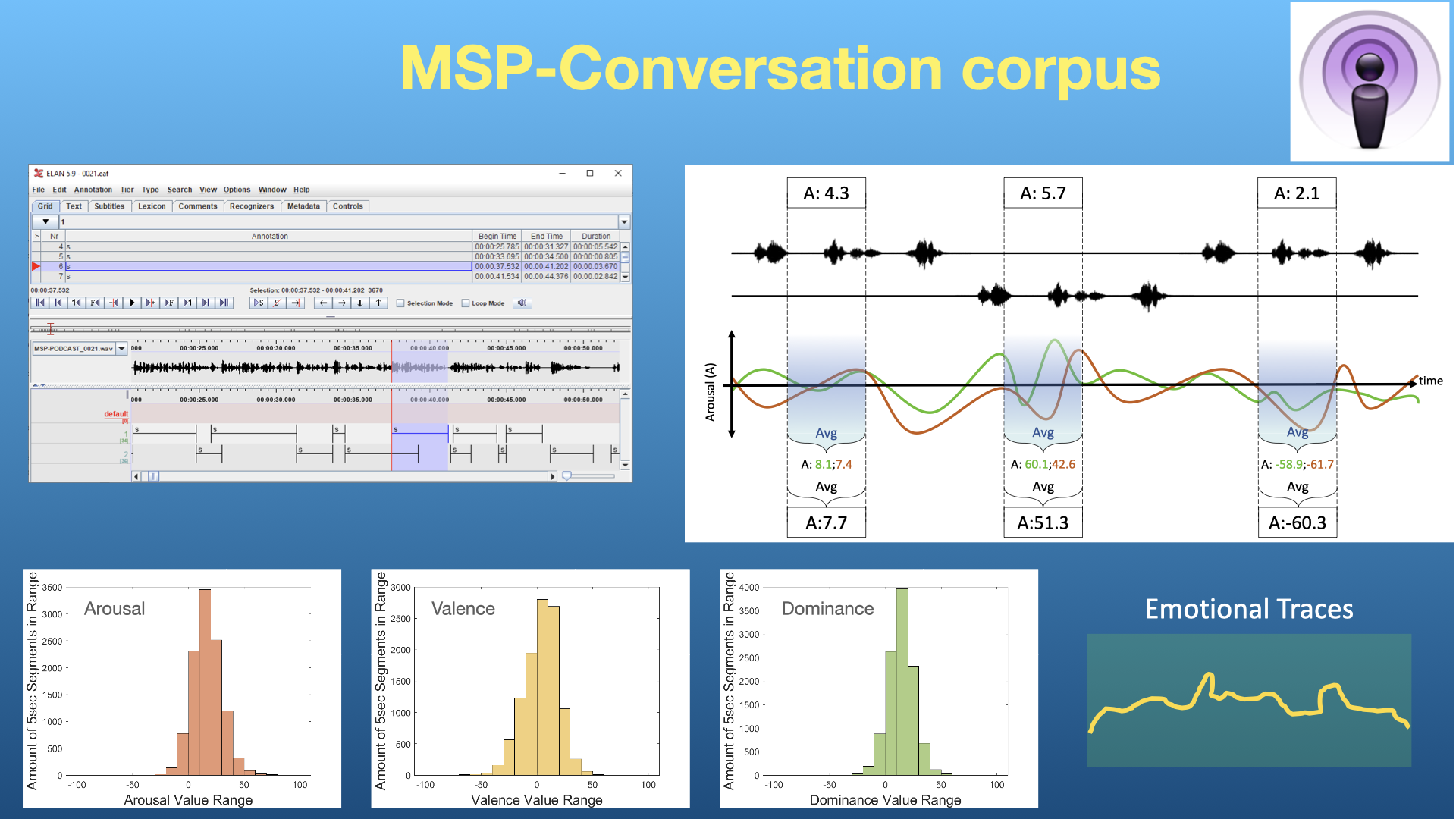 |
A key feature of the corpus is that the recordings overlap with the recordings included in the MSP-Podcast database, which contains sentence-level annotations of short segments retrieved from podcasts. The MSP-Podcast corpus is not appropriate to study contextual information, as the isolated turns are separately evaluated, missing the temporal relationship between consecutive speaking turns. The MSP-Conversation corpus complements the MSP-Podcast, providing the perfect platform to explore temporal information.
The proposed approach has the advantage that we can easily balance the emotional content and speaker demography by choosing the right podcasts. The approach does not intentionally manipulate or induce the speakers, resulting in a flexible and scalable approach to collect emotional data. The MSP-Podcast corpus is being recorded as part of our NSF project "CCRI: New: Creating the largest speech emotional database by leveraging existing naturalistic recordings" (NSF CNS: 2016719). For further information on the corpus, please read:
- Luz Martinez-Lucas, Mohammed Abdelwahab, and Carlos Busso, "The MSP-conversation corpus," in Interspeech 2020, Shanghai, China, October 2020, pp. 1823-1827. [soon cited] [pdf] [bib] [slides]
Release of the Corpus: Academic License
The corpus is now available under an Academic License (free of cost). Please download this pdf. The process requires your institution to sign the agreement. A couple of notes about this form:
Instructions:
- It has to be signed by someone with signing authority in behalf of the university (usually someone from the sponsored research office).
- The license is a standard FDP data transfer form. It should be easy for you to obtain a signature.
We emphasize that the form should only be signed by someone with signature authority in the academic
institution in order to make it a valid agreement. If the group leader or
laboratory directory does somehow have that authority, it would be fine for them
to sign, but that scenario is often highly unlikely. This is a legally binding
document that must be signed by someone with signature authority in the academic
institution. Send the signed form to Prof. Carlos Busso - ![]()
Release of the Corpus: Commercial License
Companies interested in this corpus can obtain a commercial license from UT Dallas.
The commercial license is US$10,000, which will give you access to the corpus. After a year,
we provide the opportunity to renew the agreement for US$5,000 dollar. If you renew
the agreement, we give you the current version of the corpus with all the updates
during the year (again, this is an ongoing project). If you do not renew the agreement,
then you can use the version that you received without any restriction. However,
you will not receive the new updates on the corpus, unless you enter in another
separate agreement. Please contact Carlos Busso if you are interested. - ![]()
We offer a 40% discount for companies or institutions that have an active license for the MSP-Podcast corpus ($6,000 for new license, $3,000 for renewal option).
Some of our Publications using this Corpus:
- Luz Martinez-Lucas, Mohammed Abdelwahab, and Carlos Busso, "The MSP-conversation corpus," in Interspeech 2020, Shanghai, China, October 2020, pp. 1823-1827. [soon cited] [pdf] [bib] [slides]
This material is based upon work supported by the National Science Foundation under Grant IIS-1453781. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.