MSP-Podcast corpus:
A large naturalistic speech emotional dataset
We are building the largest naturalistic speech emotional dataset in the community. The MSP-Podcast corpus contains speech segments from podcast recordings which are perceptually annotated using crowdsourcing. The collection of this corpus is an ongoing process. Version 1.11 of the corpus has 151,654 speaking turns (237 hours and 56 mins). The proposed partition attempts to create speaker-independent datasets for Train, Development, Test1, Test2, and Test3 sets.
- Test set 1: We use segments from 237 speakers - 30,647 segments
- Test set 2: We select 117 podcasts to create this test set. Instead of retrieving the samples using machine learning models, we randomly select 14,815 segments from 117 speakers. Segments from these 117 podcasts are not included in any other partition.
- Test set 3: This partition comprises 2,347 unique segments from 187 speakers, for which the labels are not publicly available. The segments have been curated to maintain a balanced representation based on primary categorical emotions (Anger, Sadness, Happiness, Surprise, Fear, Disgust, Contempt, Neutral). The release only includes the audio information. The labels, speaker information, transcription, and forced alignment information have been hidden. The researchers will be able to evaluate the results of primary emotions and emotional attributes on this partition using a web-based interface.
- Development set: We use segments from 454 speakers - 19,815 segments
- Train set: We use the remaining speech samples from 1,409 speakers - 84,030 segments. This set includes samples that we have not yet annotated their speaker identity.
Note: There is some speaker overlap between the test sets (e.g., recordings from one speaker in the Test1 set can be included in the Test2 set and/or Test3 set). Therefore, the test sets should never be used to train models if speaker-independent results are to be reported. The speakers selected for the train and development set do not overlap with the speakers in the test sets. However, data in the train set without speaker identification can potentially belong to speakers in the test sets.
 |
This corpus is annotated with emotional labels using attribute-based descriptors (activation, dominance, and valence) and categorical labels (anger, happiness, sadness, disgust, surprised, fear, contempt, neutral and other). To the best of our knowledge, this is the largest speech-emotional corpus in the community.
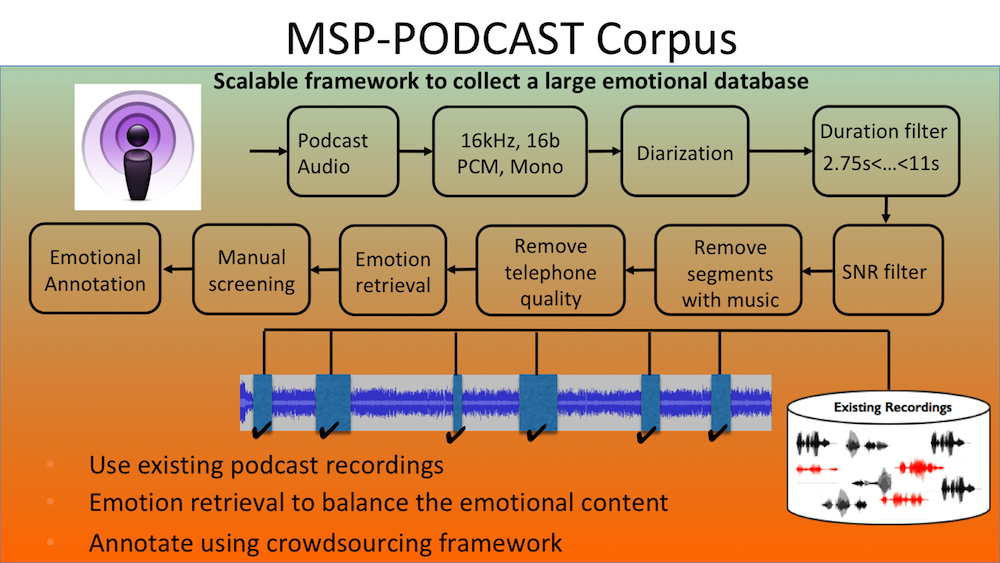
Upon downloading the podcasts, the recordings are formatted and named using a predefined protocol. Then, they are automatically segmented and analyzed so that the resulting segments include clean speech segments. We do not want to include background music, overlapped speech, or voices recorded over a telephone where the bandwidth is limited at 4KHz, neglecting spectral components that can be useful features for speech emotion recognition. Using existing algorithms, the recordings are segmented into speaking turns. The approach consider voice activity detection, speaker dialization, and music/speech recognition. The code also include a module which will estimate the noise level of the recordings using automatic algorithms (e.g., WADA SNR).
The size of this naturalistic recording provides unique opportunities to explore machine learning algorithms that require large corpora for training (e.g., deep learning). Another interesting feature of this corpus is that the emotional content is balanced, providing enough samples across the valence-arousal space. Emotion recognition systems are trained with existing emotional corpora, which are used to retrieve emotional samples that we predicted have certain emotional content. These samples are then annotated with emotional labels using crowdsourcing.
Key features of this corpus:
- We download available audio recordings with common license. We only use the podcasts that have less restrictive licenses, so we can modify, sell and distribute the corpus (you can use it for commercial product!).
- Most of the segments in a regular podcasts are neutral. We use machine learning techniques trained with available data to retrieve candidate segments. These segments are emotionally annotated with crowdsourcing. This approach allows us to spend our resources on speech segments that are likely to convey emotions.
- We annotate categorical emotions and attribute based labels at the speaking turn label
- This is an ongoing effort, where we currently have 151,654 speaking turns (237 hours and 56 mins). We collect approximately 10,000-13,000 new speaking turns per year. Our goal is to reach 400 hours.
The MSP-Podcast corpus is being recorded as part of our NSF project "CCRI: New: Creating the largest speech emotional database by leveraging existing naturalistic recordings" (NSF CNS: 2016719). For further information on the corpus, please read:
- Reza Lotfian and Carlos Busso, "Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings," IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471-483, October-December 2019. [pdf] [cited] [bib]
Release of the Corpus: Academic License
The corpus is now available under an Academic License (free of cost). Please download this pdf. The process requires your institution to sign the agreement. A couple of notes about this form:
Instructions:
- It has to be signed by someone with signing authority in behalf of the university (usually someone from the sponsored research office).
- The license is a standard FDP data transfer form. It should be easy for you to obtain a signature.
We emphasize that the form should only be signed by someone with signature authority in the academic
institution in order to make it a valid agreement. If the group leader or
laboratory directory does somehow have that authority, it would be fine for them
to sign, but that scenario is often highly unlikely. This is a legally binding
document that must be signed by someone with signature authority in the academic
institution. Send the signed form to Prof. Carlos Busso - ![]()
Release of the Corpus: Commercial License
Companies interested in this corpus can obtain a commercial license from UT Dallas.
The commercial license is US$10,000, which will give you access to the corpus. After a year,
we provide the opportunity to renew the agreement for US$5,000 dollar. If you renew
the agreement, we give you the current version of the corpus with all the updates
during the year (again, this is an ongoing project). If you do not renew the agreement,
then you can use the version that you received without any restriction. However,
you will not receive the new updates on the corpus, unless you enter in another
separate agreement. Please contact Carlos Busso if you are interested. - ![]()
Some of our Publications using this Corpus:
- John Harvill, Seong-Gyun Leem, Mohammed Abdelwahab, Reza Lotfian, and Carlos Busso, "Quantifying emotional similarity in speech," IEEE Transactions on Affective Computing, vol. to appear, 2023. [pdf] [cited] [bib]
- Wei-Cheng Lin and Carlos Busso, "Chunk-level speech emotion recognition: A general framework of sequence-to-one dynamic temporal modeling," IEEE Transactions on Affective Computing, vol. To Appear, 2023. [pdf] [cited] [bib]
- Wei-Cheng Lin and Carlos Busso, "Sequential modeling by leveraging non-uniform distribution of speech emotion," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1087-1099, February 2023. [soon cited] [pdf] [bib] li> Kusha Sridhar and Carlos Busso, "Unsupervised personalization of an emotion recognition system: The unique properties of the externalization of valence in speech," IEEE Transactions on Affective Computing, vol. 13, no. 4, pp. 1959-1972, October-December 2022. [pdf] [ArXiv 2201.07876] [cited] [bib]
- Srinivas Parthasarathy and Carlos Busso, "Semi-supervised speech emotion recognition with ladder networks," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2697-2709, September 2020. [pdf] [cited] [ArXiv 1905.02921] [bib]
- Reza Lotfian and Carlos Busso, "Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings," IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471-483, October-December 2019. [pdf] [cited] [bib]
- Mohammed Abdelwahab and Carlos Busso, "Domain adversarial for acoustic emotion recognition," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 12, pp. 2423-2435, December 2018. [pdf] [cited] [ArXiv] [bib]
- Reza Lotfian and Carlos Busso, "Curriculum learning for speech emotion recognition from crowdsourced labels," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 4, pp. 815-826, April 2019. [pdf] [cited] [ArXiv] [bib]
- Luz Martinez-Lucas, Ali N. Salman, Seong-Gyun Leem, Shreya G. Upadhyay, Chi-Chun Lee, and Carlos Busso, "Analyzing the effect of affective priming on emotional annotations," in International Conference on Affective Computing and Intelligent Interaction (ACII 2023), Cambridge, MA, USA, September 2023. [soon pdf][soon cited] [bib]
- Shreya G. Upadhyay, Woan-Shiuan Chien, Bo-Hao Su, Lucas Goncalves, Ya-Tse Wu, Ali N. Salman, Carlos Busso, and Chi-Chun Lee, "An intelligent infrastructure toward large scale naturalistic affective speech corpora collection," in International Conference on Affective Computing and Intelligent Interaction (ACII 2023), Cambridge, MA, USA, September 2023. [soon pdf][soon cited] [bib]
- Seong-Gyun Leem, Daniel Fulford, Jukka-Pekka Onnela, David Gard, Carlos Busso, "Computation and memory efficient noise adaptation of Wav2Vec2.0 for noisy speech emotion recognition with skip connection adapters," In Interspeech 2023, Dublin, Ireland, August 2023, vol. To appear. [soon cited] [pdf] [bib]
- Abinay Reddy Naini, Ali N. Salman, and Carlos Busso, "Preference learning labels by anchoring on consecutive annotations," In Interspeech 2023, Dublin, Ireland, August 2023, vol. To appear. [soon cited] [pdf] [bib]
- Nicolás Grágeda, Carlos Busso, Eduardo Alvarado, Rodrigo Mahu, and Néstor Becerra Yoma, "Distant speech emotion recognition in an indoor human-robot interaction scenario," In Interspeech 2023, Dublin, Ireland, August 2023, vol. To appear. [soon cited] [pdf] [bib]
- Huang-Cheng Chou, Lucas Goncalves, Seong-Gyun Leem, Chi-Chun Lee, Carlos Busso, "The importance of calibration: Rethinking confidence and performance of speech multi-label emotion classifiers," In Interspeech 2023, Dublin, Ireland, August 2023, vol. To appear. [soon cited] [pdf] [bib]
- Seong-Gyun Leem, Daniel Fulford, Jukka-Pekka Onnela, David Gard, Carlos Busso, "Adapting a self-supervised speech representation for noisy speech emotion recognition by using contrastive teacher-student learning," In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece, 2023. [soon cited] [pdf] [bib]
- Wei-Cheng Lin and Carlos Busso, "Role of lexical boundary information in chunk-level segmentation for speech emotion recognition," In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece, 2023. [soon cited] [pdf] [bib]
- Abinay Reddy Naini, Mary A. Kohler, and Carlos Busso, "Unsupervised domain adaptation for preference learning based speech emotion recognition," In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece, 2023. [soon cited] [pdf] [bib]
- Shreya G. Upadhyay, Luz Martinez-Lucas, Bo-Hao Su, Wei-Cheng Lin, Woan-Shiuan Chien, Ya-Tse Wu, William Katz, Carlos Busso, Chi-Chun Lee, "Phonetic anchor-based transfer learning to facilitate unsupervised cross-lingual speech emotion recognition," In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece, 2023. [soon cited] [pdf] [bib]
- Woan-Shiuan Chien, Shreya Upadhyay, Wei-Cheng Lin, Ya-Tse Wu, Bo-Hao Su, Carlos Busso, Chi-Chun Lee, "Monologue versus conversation: Differences in emotion perception and acoustic expressivity," International Conference on Affective Computing and Intelligent Interaction (ACII 2022), Nara, Japan, October 2022. [soon cited] [pdf] [bib]
- Huang-Cheng Chou, Chi-Chun Lee, Carlos Busso, "Exploiting co-occurrence frequency of emotions in perceptual evaluations to train a speech emotion classifier," in Interspeech 2022, Incheon, South Korea, September 2022. [pdf] [cited] [bib]
- Seong-Gyun Leem, Daniel Fulford, Jukka-Pekka Onnela, David Gard, Carlos Busso, "Not all features are equal: Selection of robust features for speech emotion recognition in noisy environments," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), Singapore, May 2022. [pdf] [cited] [bib]
- Huang-Cheng Chou, Wei-Cheng Lin, Chi-Chun Lee, Carlos Busso, "Exploiting annotators' typed description of emotion perception to maximize utilization of ratings for speech emotion recognition," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), Singapore, May 2022. [pdf] [cited] [bib]
- Kusha Sridhar, Wei-Cheng Lin and C. Busso, "Generative approach using soft-labels to learn uncertainty in predicting emotional attributes," in International Conference on Affective Computing and Intelligent Interaction (ACII 2021), Nara, Japan, September-October 2021 [pdf] [cited] [bib] [slides]
- Seong-Gyun Leem, Daniel Fulford, Jukka-Pekka Onnela, David Gard and Carlos Busso, "Separation of emotional and reconstruction embeddings on ladder network to improve speech emotion recognition robustness in noisy conditions," in Interspeech 2021, Brno, Czech Republic, August-September 2021. [pdf] [cited] [bib] [slides]
- Wei-Cheng Lin, Kusha Sridhar, and Carlos Busso, "DeepEmoCluster: A semi-supervised framework for latent cluster representation of speech emotions," in IEEE international conference on acoustics, speech and signal processing (ICASSP 2021), Toronto, ON, Canada, June 2021, pp. 7263-7267. [pdf] [cited] [bib] [slides]
- Wei-Cheng Lin and Carlos Busso, "An efficient temporal modeling approach for speech emotion recognition," in Interspeech 2020, Shanghai, China, October 2020. [soon cited] [pdf] [bib]
- Kusha Sridhar and Carlos Busso, "Ensemble of students taught by probabilistic teachers to improve speech emotion recognition," in Interspeech 2020, Shanghai, China, October 2020. [soon cited] [pdf] [bib]
- Kusha Sridhar and Carlos Busso, "Modeling uncertainty in predicting emotional attributes from spontaneous speech," in IEEE international conference on acoustics, speech and signal processing (ICASSP 2020), Barcelona, Spain, May 2020, pp. 8384-8388. [soon cited] [pdf] [bib] [slides]
- Kusha Sridhar and Carlos Busso, "Speech emotion recognition with a reject option," in Interspeech 2019, Graz, Austria, September 2019, pp. 3272-3276 [pdf] [cited] [bib] [poster]
- Mohammed Abdelwahab and Carlos Busso, "Active learning for speech emotion recognition using deep neural network," in International Conference on Affective Computing and Intelligent Interaction (ACII 2019), Cambridge, UK, September 2019, pp. 441-447. [pdf] [cited] [bib] [slides]
- Michelle Bancroft, Reza Lotfian, John Hansen, and Carlos Busso, "Exploring the Intersection Between Speaker Verification and Emotion Recognition," in International Workshop on Social & Emotion AI for Industry (SEAIxI), Cambridge, UK, September 2019, pp. 337-342. [soon cited] [pdf] [bib] [slides]
- John Harvill, Mohammed AbdelWahab, Reza Lotfian, and Carlos Busso, "Retrieving speech samples with similar emotional content using a triplet loss function," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, May 2019, pp. 3792-3796. [pdf] [cited] [bib] [poster]
- Srinivas Parthasarathy and Carlos Busso, "Ladder networks for emotion recognition: Using unsupervised auxiliary tasks to improve predictions of emotional attributes," in Interspeech 2018, Hyderabad, India, September 2018, pp. 3698-3702. [pdf] [cited] [ArXiv] [bib] [poster]
- Kusha Sridhar, Srinivas Parthasarathy and Carlos Busso, "Role of regularization in the prediction of valence from speech," in Interspeech 2018, Hyderabad, India, September 2018, pp. 941-945. [pdf] [cited] [bib] [slides]
- Srinivas Parthasarathy and Carlos Busso, "Preference-learning with qualitative agreement for sentence level emotional annotations," in Interspeech 2018, Hyderabad, India, September 2018, pp. 252-256. [pdf] [cited] [bib] [poster]
- Reza Lotfian and Carlos Busso, "Predicting categorical emotions by jointly learning primary and secondary emotions through multitask learning," in Interspeech 2018, Hyderabad, India, September 2018, pp. 951-955. [pdf] [cited] [bib] [slides]
- Najmeh Sadoughi and Carlos Busso, "Expressive speech-driven lip movements with multitask learning," in IEEE Conference on Automatic Face and Gesture Recognition (FG 2018), Xi'an, China, May 2018, pp. 409-415. [pdf] [cited] [bib] [poster]
- Mohammed Abdelwahab and Carlos Busso, "Study of dense network approaches for speech emotion recognition," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2018), Calgary, AB, Canada, April 2018, pp. 5084-5088. [pdf] [cited] [bib] [poster]
- Reza Lotfian and Carlos Busso, "Formulating emotion perception as a probabilistic model with application to categorical emotion classification," in International Conference on Affective Computing and Intelligent Interaction (ACII 2017), San Antonio, TX, USA, October 2017, pp. 415-420. [pdf] [cited] [bib] [slides]
- Srinivas Parthasarathy and Carlos Busso, "Predicting speaker recognition reliability by considering emotional content," in International Conference on Affective Computing and Intelligent Interaction (ACII 2017), San Antonio, TX, USA, October 2017, pp. 434-436. [pdf] [cited] [bib] [poster]
- Srinivas Parthasarathy and Carlos Busso, "Jointly predicting
arousal, valence and dominance with multi-task learning,"
in Interspeech 2017, Stockholm, Sweden, August 2017, pp. 1103-1107.
[pdf]
[cited]
[bib]
[slides]
Nominated for Best Student Paper at Interspeech 2017! - Srinivas Parthasarathy, Chunlei Zhang, John H.L. Hansen, and Carlos Busso, " A study of speaker verification performance with expressive speech," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2017), New Orleans, LA, USA, March 2017, pp. 5540-5544. [pdf] [cited] [bib] [poster]
This material is based upon work supported by the National Science Foundation under Grant IIS-1453781. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.