Human-Centered Research Lab
Welcome to the Multimodal Signal Processing (MSP) Laboratory
In this website, you will find an overview of the exciting activities that are happening at Multimodal Signal Processing (MSP) laboratory. It also introduces the faculty and students involved in the lab.
Spotlight
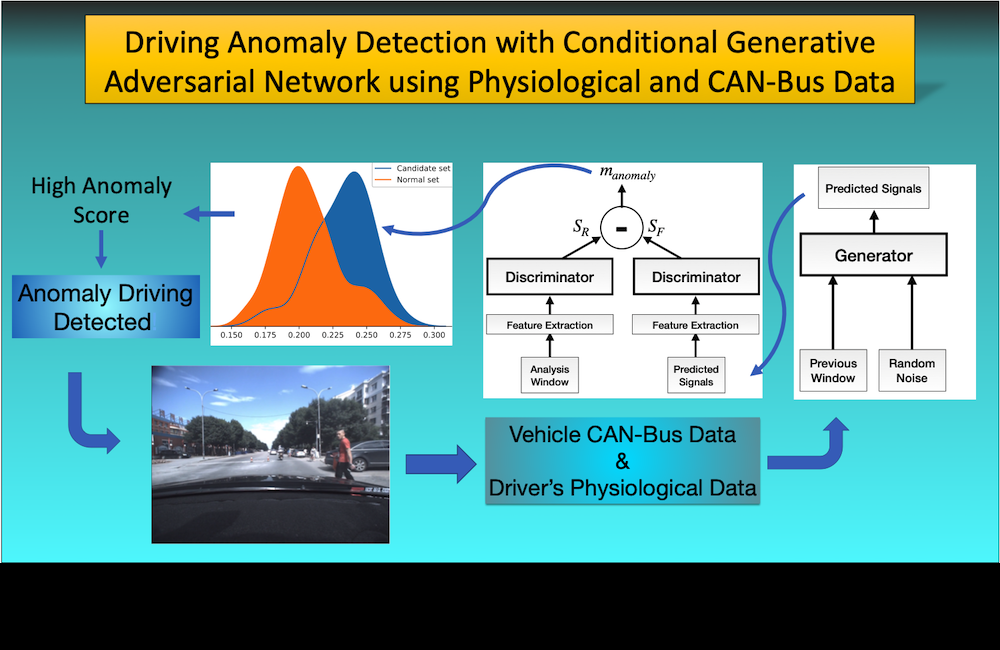
Can we detect driving anomalies without any supervision? Our approach using conditional GAN, where signal predictions contrasted with actual data.
[pdf]
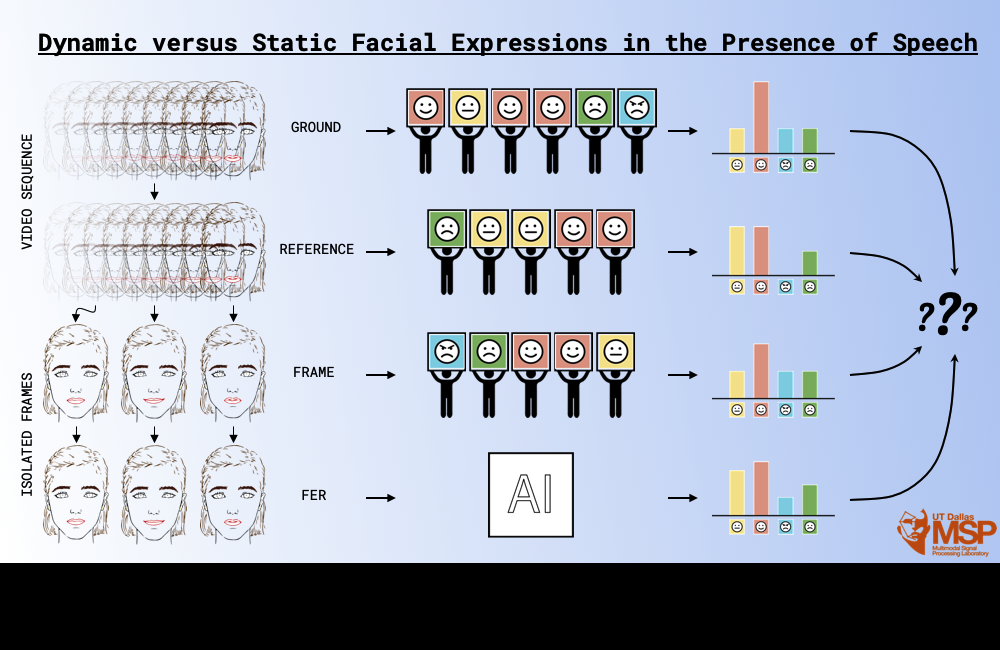
It is not enough to use an image-based facial expression recognition system to detect emotion from videos, even if it has human level performance.
[pdf]
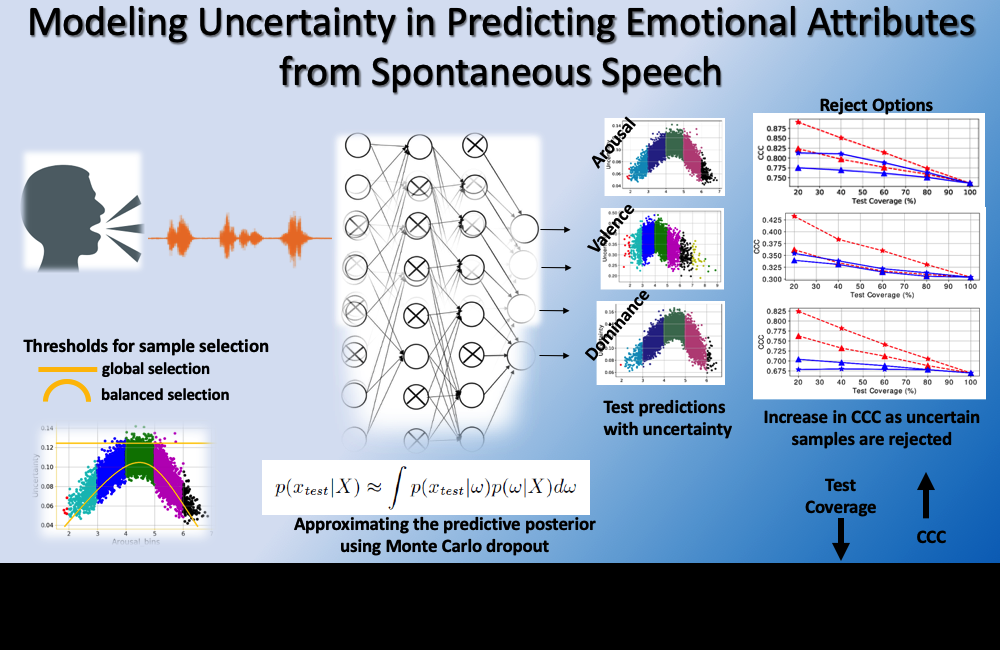
Studies on speech emotion recognition have often focused on accuracy of the predictions. We argue that systems should also estimate their certainty.
[pdf]
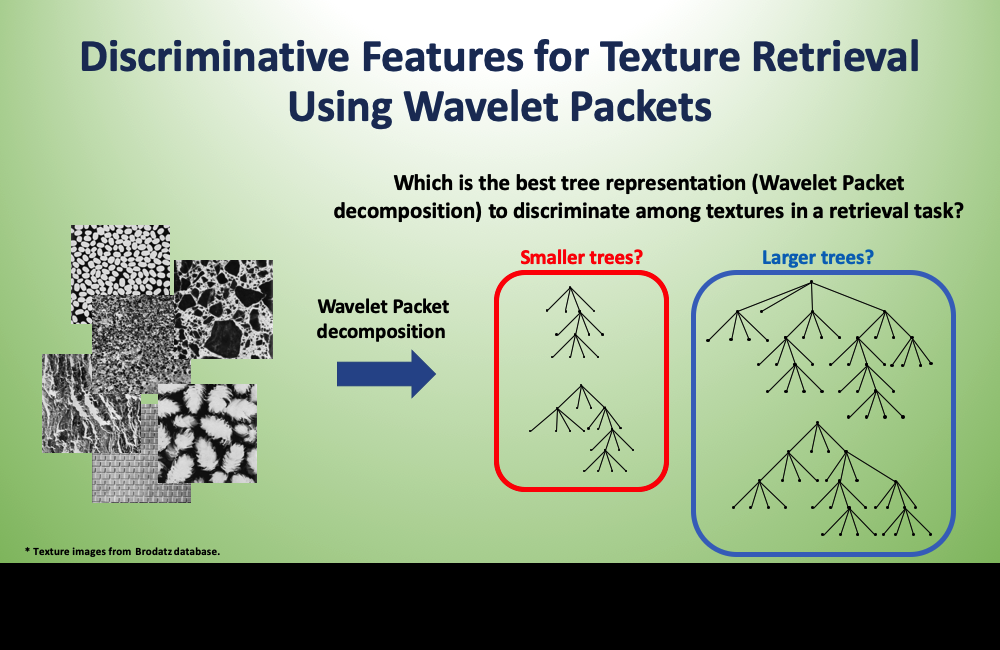
We propose a novel Wavelet Packets (WPs) solution for image segmentation that offers optimal balance between estimation and approximation errors.
[pdf]
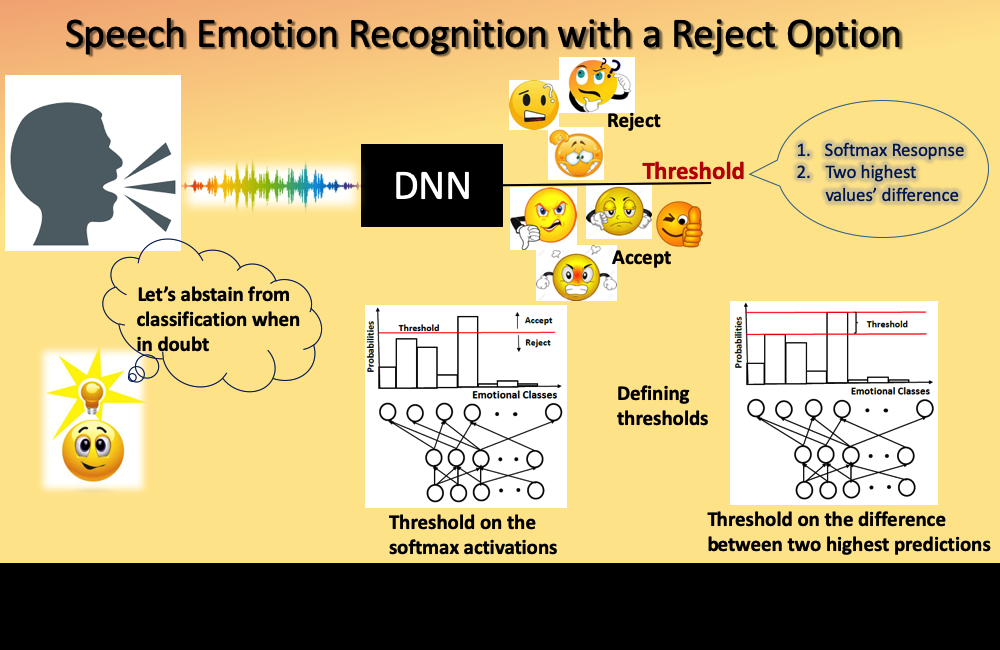
Would you like your speech emotion recognition (SER) system to warn you if its prediction confidence is low? We propose a SER system with reject option.
[pdf]
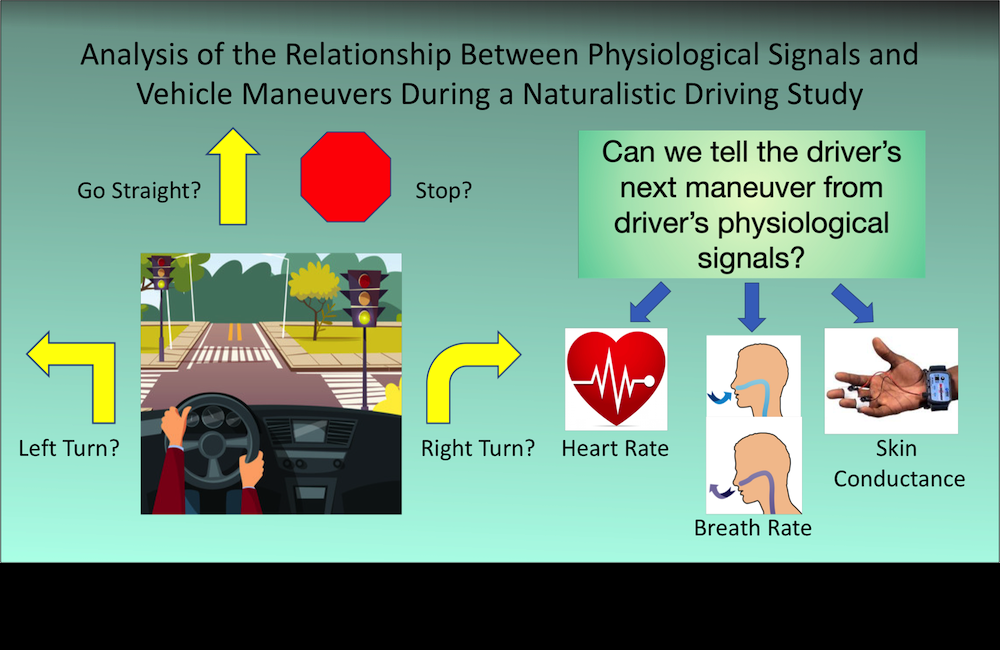
Physiological signals can be very useful for in-vehicle safety systems. We evaluate the relation of heart rate, breath rate, and EDA with driving maneuvers.
[pdf]
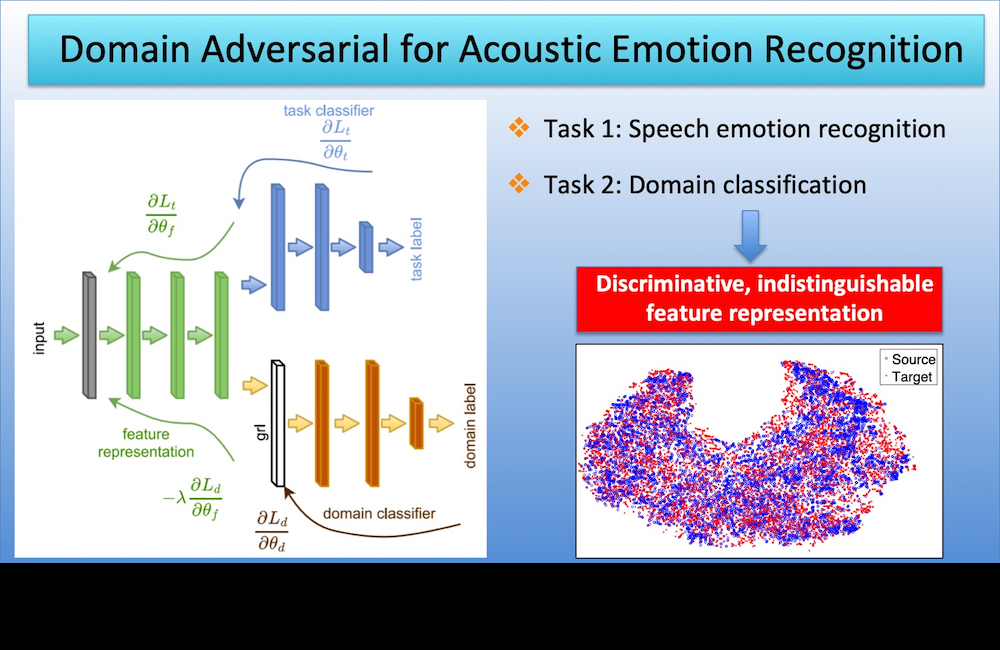
This approach is a powerful and effective framework to leverage unlabeled data for speech emotion recognition. Learn more in our paper.
[pdf]
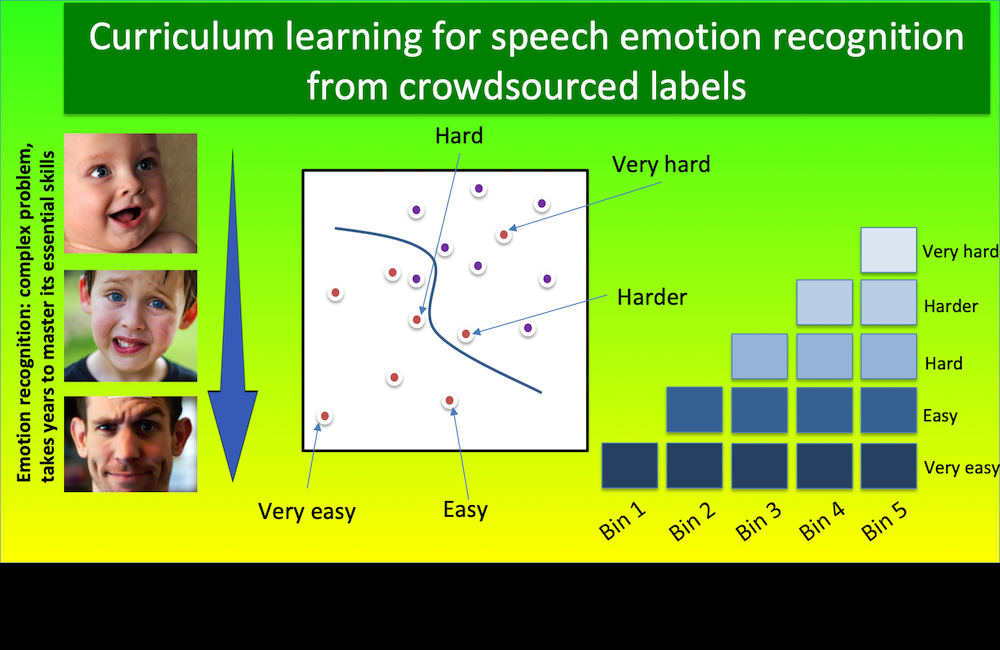
We need to know basic concepts before learning hard concepts. The same idea is true in machine learning. We demonstrate the benefits of curriculum learning for SER.
[pdf]
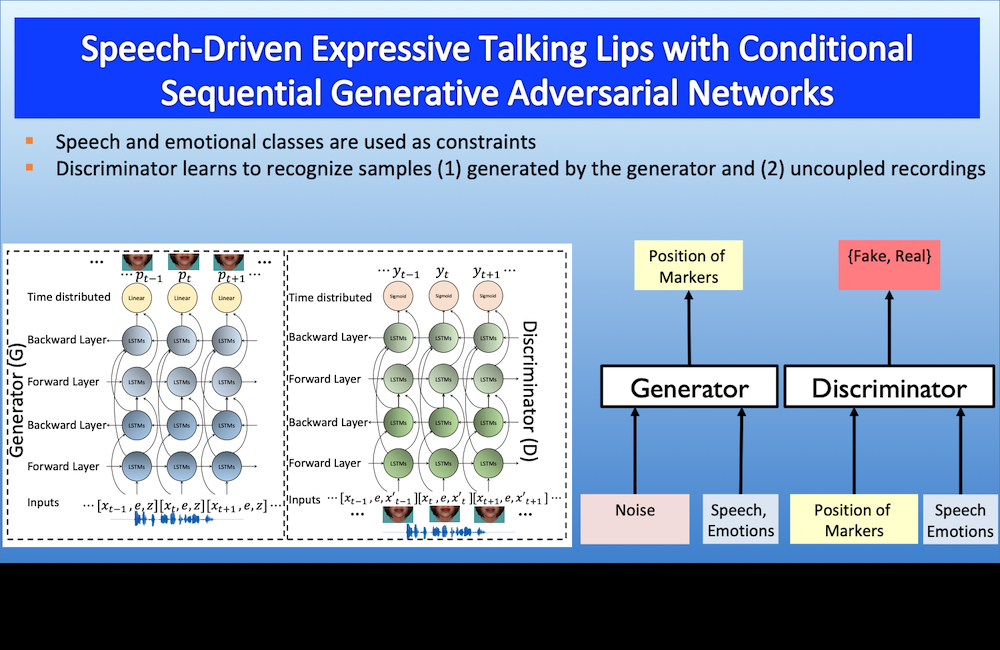
We use conditional sequential GAN to synthesize expressive lip motion driven by speech. This is a powerful generative model where lip motions are constrained by speech.
[pdf]
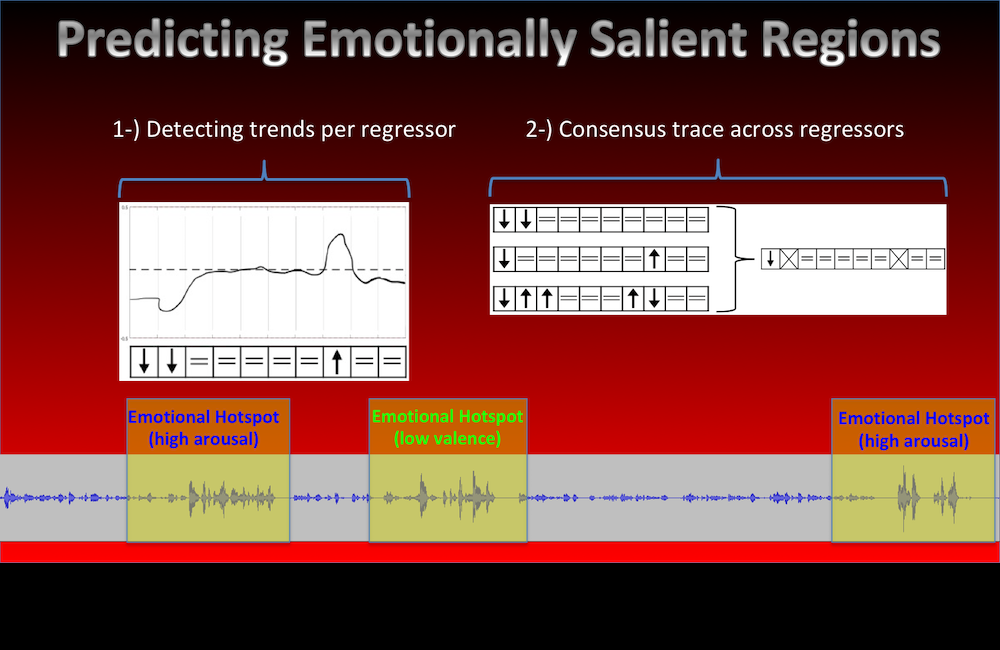
This study aims to identify emotionally salient segments from speech during longer interactions. More details in our paper.
[pdf]
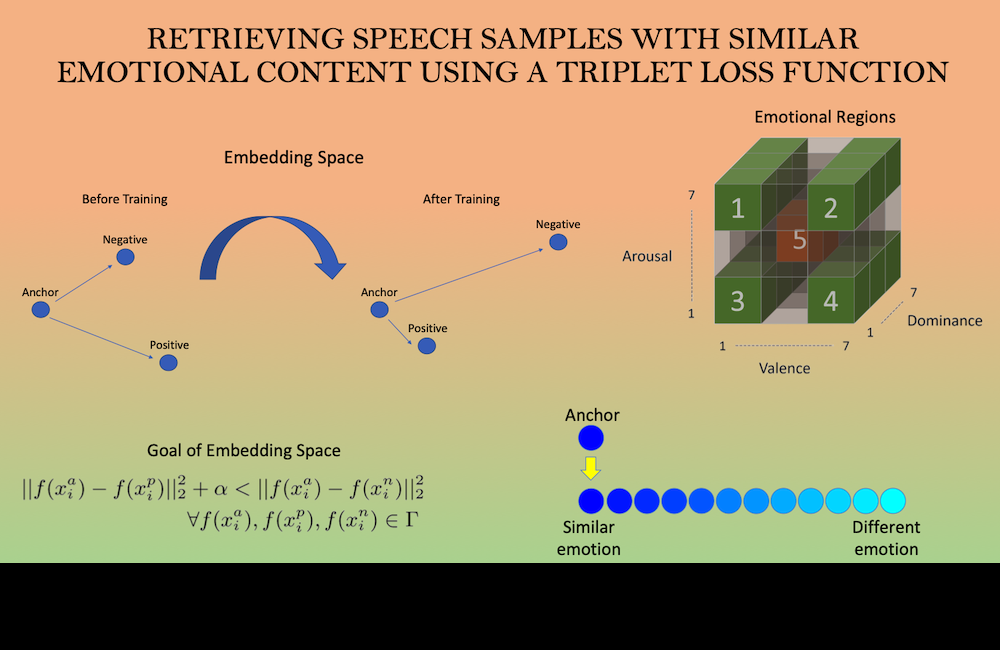
This study presents a novel formulation in affective computing. We aim to retrieve sentences with similar emotional content as an anchor sentence.
[pdf]
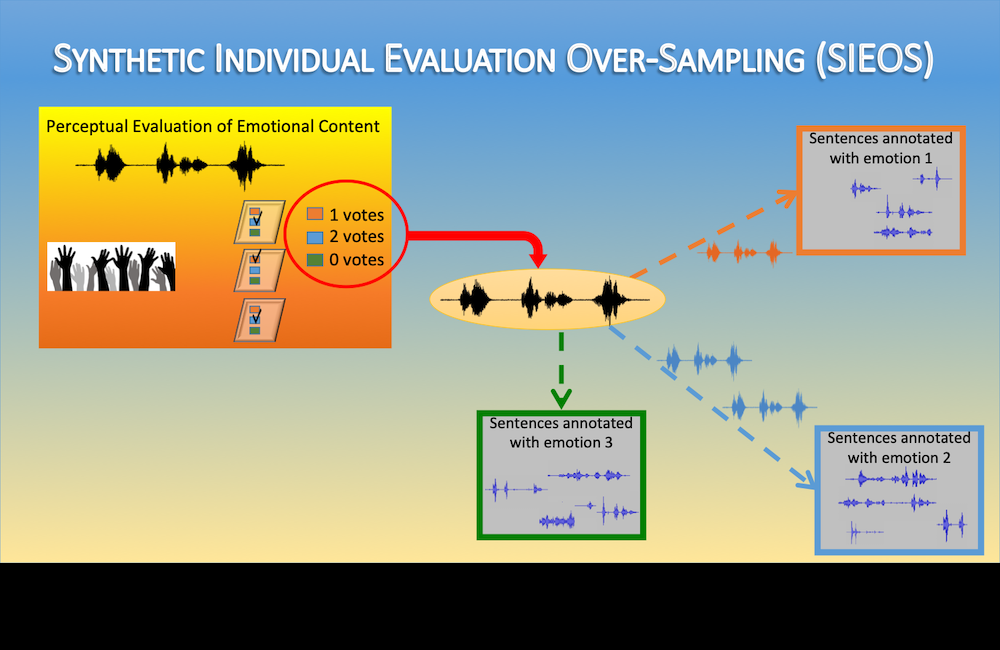
We explore individual evaluations before estimating consensus labels to augment the training set with synthetic samples. Simple but effective.
[pdf]
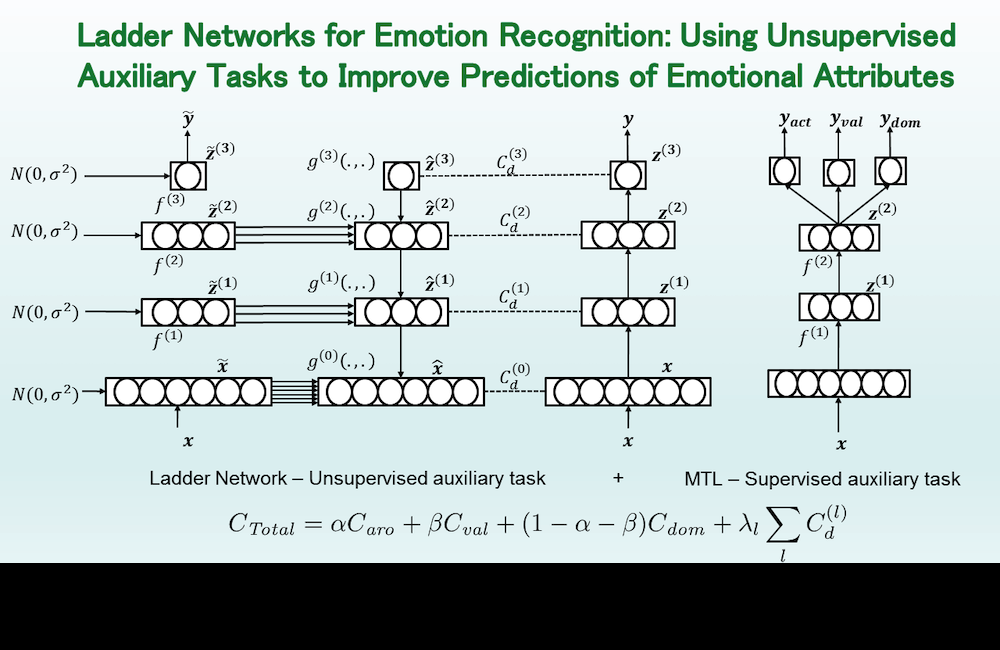
How to use unlabeled data in speech emotion recognition? What about unsupervised auxiliary tasks that are jointly solved with the supervised task? Our paper here.
[pdf]

What is easier to answer? 1) What is the valence of a sentence? 2) Among 2 sentences, which is the most positive? We argue about the ordinal nature of emotion.
[pdf]
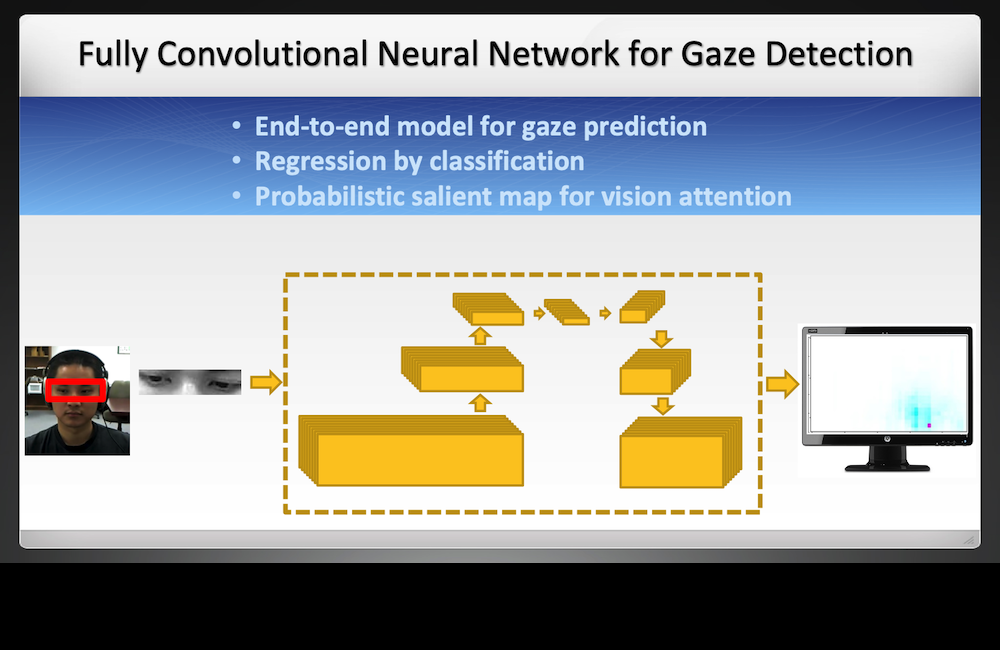
A novel framework for gaze prediction using a CNN-based probability model. A power non-parametric models for visual attention.
[pdf]
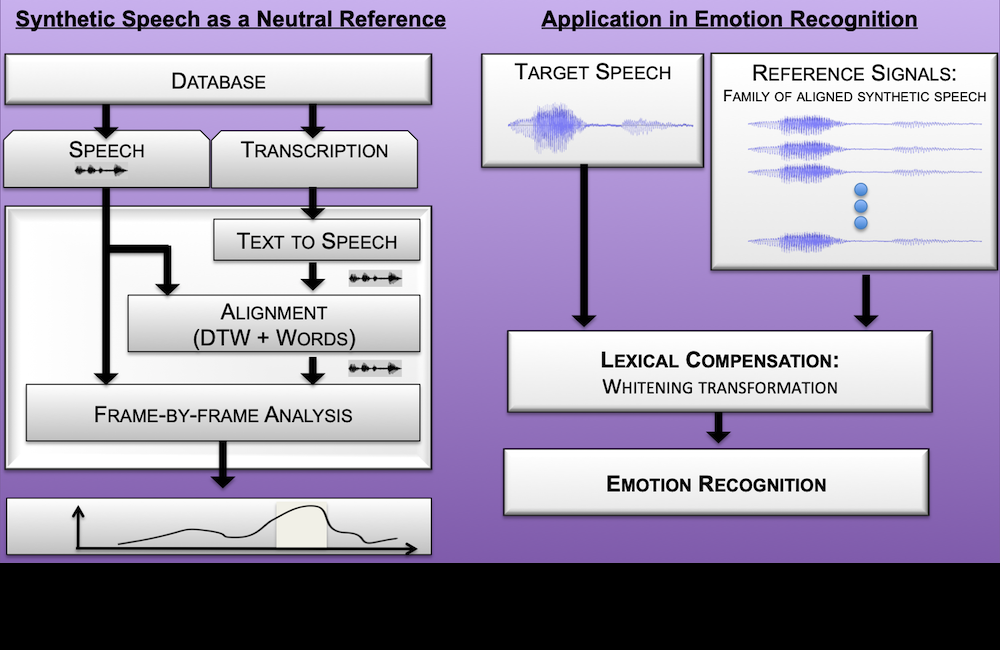
How to build a reference model to contrast expressive speech? We propose a formulation based on synthetic speech. Read more in our paper.
[pdf]
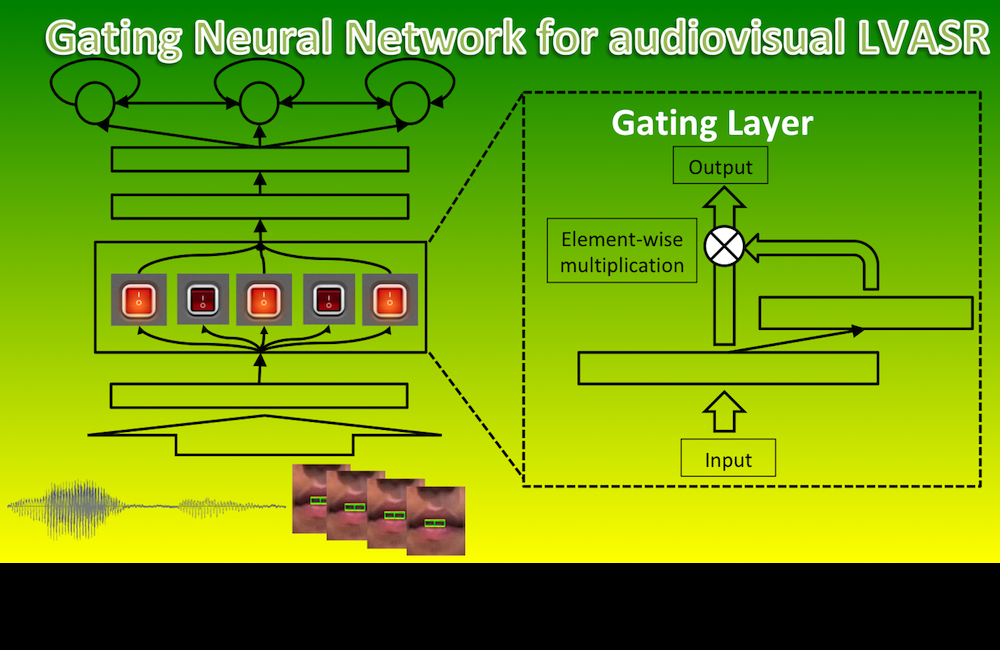
We developed an audiovisual LVASR system that works better or equal than an audio-based ASR, even when the visual features are not very discriminative.
[pdf]
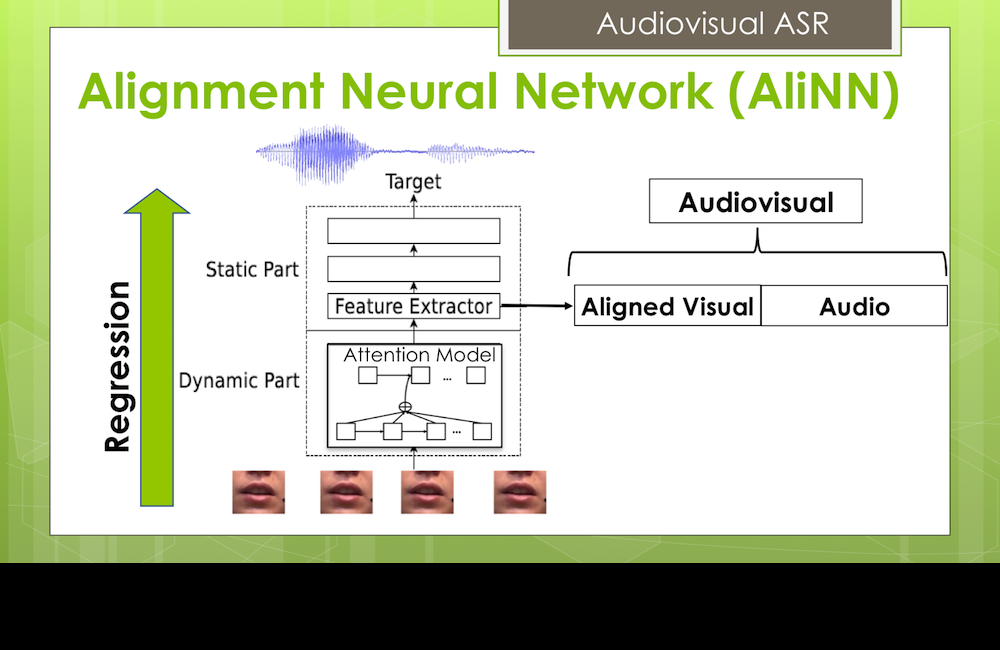
Lip motion is not perfectly synchronized with speech (e.g., anticipatory movements). We compensate for this phase difference with our new AliNN framework.
[pdf]
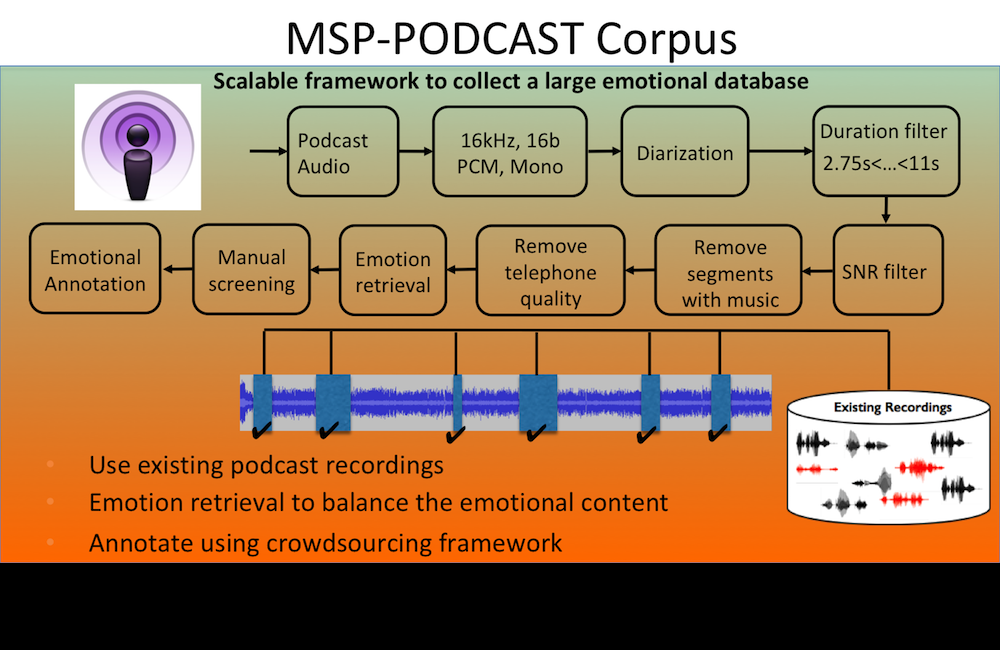
We do not have a big database for speech emotion recognition, until now! Learn more about the MSP-Podcast database in our paper.
[pdf]

Our solution to record head pose data in real driving recordings. Read more in our paper
[pdf]
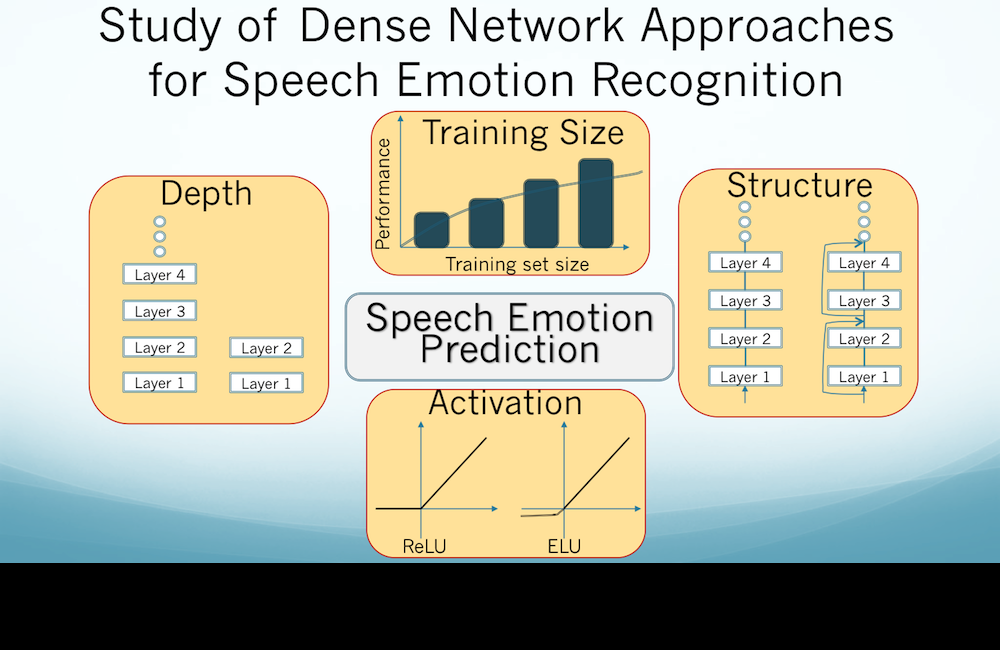
Can we train deep models for speech emotion recognition? Read our experience in our paper
[pdf]
About the MSP laboratory
The MSP laboratory is dedicated to advance technology in the area human-centered multimodal signal processing. We are looking at theoretical problems with practical applications. Our goal is to develop methods, algorithms and models to recognize and synthesize human verbal and non-verbal communication behaviors to improve human machine interaction.
Our current research includes:
- Affective computing
- Speech, video and multimodal processing
- Multimodal human-machine interfaces
- Analysis and modeling of verbal and non-verbal interaction
- Human interaction analysis and modeling
- Multimodal speaker identification
- Meeting analysis and intelligent meeting spaces
- Machine learning methods for multimodal processing
The MSP lab was established by Prof. Carlos Busso in August 2009. He is also the director of the group.
The MSP lab is part of the Erik Jonsson School of Engineering and Computer Science at The University of Texas at Dallas .

(c) Copyrights. All rights reserved.